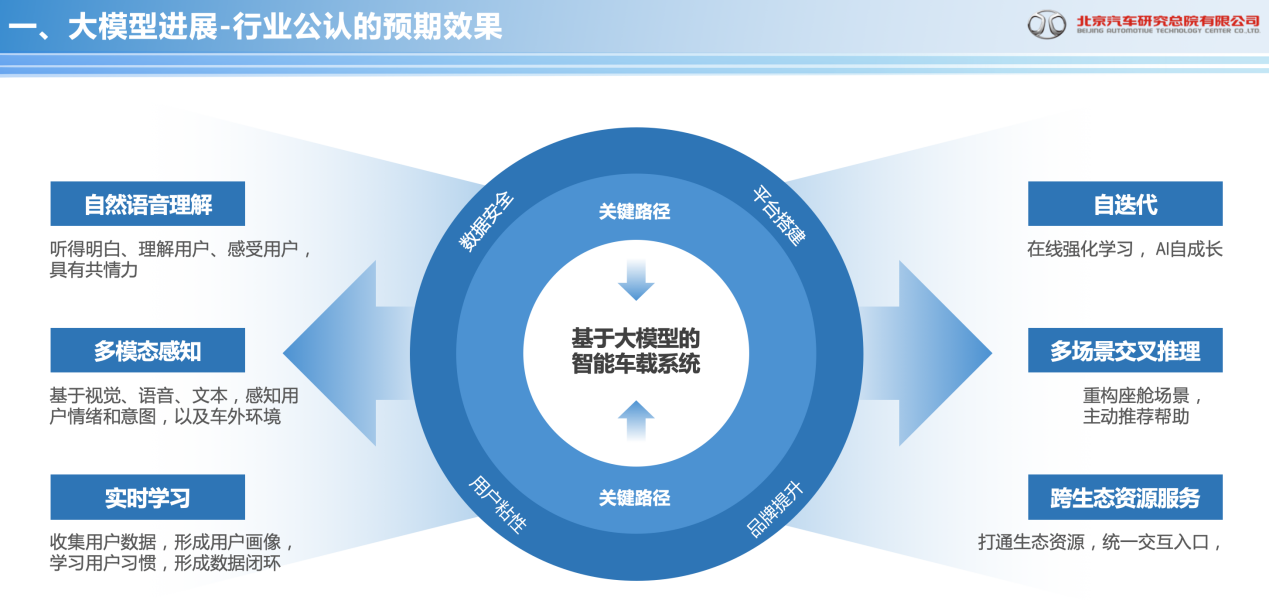
未来,大模型将全面赋能智能座舱,给予座舱深度进化。大模型技术的多模态特点可以综合处理语音、视觉、触觉等多种类型的数据,是智能座舱能更全方位地感知乘客和驾驶员的需求,提供多模态且更专业化、定制化的服务。
同时,大模型上车也带来诸多挑战。2024年3月13日,在第五届软件定义汽车论坛暨Autosar中国日上,北京汽车研究总院有限公司智能座舱总师赵亨利提到三大挑战,一是大模型需要挑战更高的算力要求,巨量的训练、精调和推理需要大量的算力资源,而在当前算力供不应求、算力价格高居不下的背景下,车企独立训练大模型难度和成本极高。全部委托外司容易也面临挑战。
二是对车端算力需求亦大幅增加,如何在车载芯片上进行高效的推理,同时不干扰其他常规算法的正常运行是一个挑战。三是对算法技术提出更高的要求。四是多模态数据的收集、获取与整合本身也有一定难度。多模态交互下涉及到超声波雷达、激光雷达、毫米波雷达以及摄像头、GPS、语音收集等多类传感器数据,但数据形式、来源不同,带有不同触发时间戳。另外,还有合法合规和隐私保护、大语言模型内容风控等问题。

赵亨利 | 北京汽车研究总院有限公司智能座舱总师
以下为演讲内容整理:
大模型进展
近两年,随着ChatGPT的出现,各种参数规模、数据量和算力资源等从比较单一的系统成长为通用型,其用处越来越广泛,将给汽车行业带来颠覆性的影响。
智能座舱作为汽车与用户人机交互的窗口,在车上所扮演的角色十分重要。以前的智能化主要是语音交互,比如对车下达指令开窗开门等,实际上并不能满足用户的真实期待。AI引入汽车后,将改变这一现状。
当前大模型仍旧有许多难以克服的问题。一是幻觉问题。大模型的底层原理是基于概率,其结果只要能够形成自己的逻辑闭环即可,因此有时候会生成一些人类无法理解的回答。有时大模型还会在自己的自洽逻辑中生成一些违背人性的内容,如提问在《红楼梦》众多女性角色中选择一切最适合做贾宝玉太太的人,大模型给出的结果是贾母,因为贾母的个人修养、家庭背景、气质、能力等都十分合适,但从实际来看,贾母是贾宝玉的奶奶,有违伦理。
二是新鲜度问题。对于一些高时效性的问题,大模型是无法回答的。比如我需要大模型告诉我电影院正在放映的电影中哪一部最好看,由于数据无法实时更新,大模型无法完成该任务。
三是数据安全。车厂是需要进行数据上云的,每时每刻都会产生大量数据,要保障好相关安全。而在使用AI能力的同时,需要将一些数据对外公开,会产生相关问题。如果不对外公开,就需要自己搭建模型,成本极大。
四是成本费用。规模越大,参数越多,成本就会越高。
大模型是一个系统工程,我们将座舱与大模型嫁接是希望其能够拓展汽车功能,为用户提供更好的体验。我们希望能够将大模型与行车、停车、维修、保养等各个生态打通,进行整体布局。
大模型上车后所带来的最明显的变化就是对交互的改善。以前的汽车是语音为第一交互,可以在车辆设定范围内进行提问,不是很智能,用户体验感不佳。引进大模型后,大模型的在线强化学习能力可以为用户提供更好的服务。
图源:演讲嘉宾素材
此外,多场景交叉推理也是我们所期待的大模型上车后带来的效果。用户的需求是复杂的,需要更多生态,希望车辆的技术能力相配合,能够形成全方面、立体的满足人类完整需求的场景,而大模型有望将APP内的生态资源打通。
相比于以前简单的回应,大模型上车后能够充当助理身份,会针对你所提出的要求给出一个详细的方案,将方案与车辆、生态、基础设施等进行联动,并进行多层次对话。
应用创新
我们发现,当前车上的智能座舱功能越来越多,但有许多功能是用户无法使用的。基于此,我们会通过智能化引导让用户更好进行操作。
最开始人机交互是短节式的命令,只能说简短的几个字的命令。之后是人工交互系统,后台可以监测车辆状态,人工坐席提供信息查询、导航路线设置、酒店预定、车辆控制和紧急救援等服务。再然后进入了弱人工智能时代,语言泛化做得较好,车辆能够识别和执行某些测定范围的工作和任务。而到了模型时代,用户说什么它都能理解,这也是我们当前的重要研发方向,我们希望能构建一个百模组合的平台。
针对大模型的发展,我们有许多战略思考。首先,当前的ChatGPT、Sora等都是单向性系统,难以满足用户的多元需求。我们希望能够建立一个类似插拔方式的大模型平台,在识别用户的新需求后,采取相符的模型,在模型之间进行组合,为用户提供整体的多元化服务。
第二,万物感知分为向外和车内两种,向外更多是打通互联网生态资源和应用壁垒。以往车内的每一个功能都需要进行分析,看主线分析数据矩阵和通信等,各单元协同开发。而今汽车内部等功能越来越多,当实现SOA原子化服务后,我们可以通过随意的组合和主动推荐,让其组合更多新功能,壮大汽车能力。
第三,我们希望能够实现反璞归一。对于用户的需求和意图,完全通过自然语义对话的形式展开。外部生态的调取都可在大模型的调度下,在合适的时间基于合适的情况推送给合适的人。
硬件系统
大模型需要许多算力搭载云端进行解决,但云端存在部分问题。未来数据上云可能变得单一化,我们所用的东西不具备特色,难以进行宣传。考虑到成本和现实因素,我们希望在算力有限的情况下优化大模型,提升服务。
下图是我们所设想的大模型平台架构。中间以基座大模型和车厂自己的微调大模型实现多模态、自学习、内容生成、数字孪生等,以数据源为输入,以任务输出为output,为用户提供各种主动化的场景。这一过程中需要车端、云端、数据端,数据端数据一般来源于车厂,共有数据来自互联网。我们还需要一个语音系统、一个场景引擎,将这些规则和能力进行主动组织和推送。

图源:演讲嘉宾素材
我们会将车机端SOA化,整合整车原子能力,为大模型引擎提供服务原料。此外还会基于用户偏好和时机的主动触达,让用户感受到被尊重、被理解,提供情绪价值。
未来趋势
大模型全面赋能能够让座舱实现更加深度的进化。大模型技术赋予座舱更准确、更流畅的语音识别功能,更丰富的知识储备与语义理解能力,并进行拟人交互,使语音交互更自然。众多车企已先从车载语音助手角度入手,推进大模型在座舱中的应用。
大模型技术的多模态特点可以综合处理语音、视觉、触觉等多种类型的数据,是智能座舱能更全方位地感知乘客和驾驶员的需求,提供多模态且更专业化的服务。同时,智能座舱通过运用 AI 大模型,将能提供千人千面的语音识别、娱乐信息及驾驶辅助个性化定制服务,并将智能座舱的功能向更精细、智能和个性化的环境控制、健康管理、娱乐信息与车辆状况监测等诸多应用场景拓展,让智能座舱经历一次深刻的进化。
在当前算力供不应求、算力价格高居不下的背景下,车企独立训练大模型难度和成本极高。根据英伟达100的算力和GPU数量的线性关系,我们想要的越多就要投入越多。
此外,不论是大模型还是小模型,由于每个车厂的数据和用户有所不同,我们需要对模型进行优化。在算力有限的情况下,如何做到最优解、提供更多服务是我们需要探讨的命题。
算法研发也是大模型上车的难点,多模态交互对算法技术提出了更高要求。多模态交互引入了更大量、更高质量、更多样化的数据,因此需要优化算法研发和硬件配置以提高模型性能、泛化能力和响应速度。算法研发不仅需要考虑初步设计和实现,还要关注模型的持续更新、学习、优化和微调。
多模态交互下涉及到超声波雷达、激光雷达、毫米波雷达以及摄像头、GPS、语音收集等多类传感器数据,但数据形式、来源不同,带有不同触发时间戳,如何有效的收集、整合不同类型的数据是车企在进行多模态上车前需要突破的难点。
为应对AIGC的快速发展,国家网信办、国家发改委、教育部等七部门于2023年7月发布了《生成式人工智能服务管理暂行办法》,对人工智能的服务安全等进行了详细规定,这也是全球首部AIGC领域的监管法规。
除了这部专门的监管法规外,我国在科技发展、网络安全、个人信息保护、互联网信息等多个方面已发布了多项法律、行政法规等规范性文件,构成了人工智能领域多层级、多角度的规范治理体系。
(以上内容来自北京汽车研究总院有限公司智能座舱总师赵亨利于2024年3月12日-14日在第五届软件定义汽车论坛暨AUTOSAR中国日发表的《人工智能时代探索智能座舱软件的未来》主题演讲。)