美国的CES展,长久以来都是人们观察全球科技风向的一个重要风向标。在2024年的CES展上,两位人工智能领域的专家,李飞飞和吴恩达做了一场对谈,在这场谈话中,他们提及了一个足以影响自动驾驶行业的关键点。
那就是,AI大模型开始从“大语言模型”向“大视觉模型”的转变,AI大模型不但能理解语言,还能生成图像,还有对图像进行分析,让计算机更好地理解图像的含义,从而给自动驾驶带来质的飞跃。
对此,本文分为两部分:
为什么李飞飞和吴恩达会说“大视觉模型”将给自动驾驶带来质的飞跃?
为什么我们对自动驾驶的AI大模型别入戏太深?
大视觉模型会带来颠覆性革命吗?
当一个人驾驶车辆时,不是简单地把着方向盘,控制着油门和刹车,还要处理很多复杂的事情。
你要看交通信号,你要看各种路边的标志物,你要判断路上有什么东西。如果前面路上有一只小鸭子在慢慢走,你得踩刹车;但是如果是一只鸟,你可以想象车开过去它就会飞走,你就不用减速。如果路上有个塑料袋,你可以直接碾压过去;但如果那是个石头,你就必须绕着走。
你对路面状况有深刻的理解,这种理解和你的生活阅历、和你平时积累的经验有关。最起码你得知道塑料袋是什么,石头是什么,鸟是什么,但汽车并不知道。
要想让汽车知道这些东西,那这背后涉及的技术可太难了。现有的图形识别能力,哪怕把障碍物换个角度,计算机都看不出来。更何况人的路面知识无穷无尽,你根本就没办法把每个知识都告诉计算机,而它自己根本没有思考能力。
当下,自动驾驶搞的都是狭义AI,走的是机器学习的路线。计算机把路上的所有物体,包括建筑物、其他的车、行人都当成是三维模型,它不再试图理解这些物体。

计算机只关心这些物体的移动趋势,估算每个物体的速度,预测它的路线,看看跟车的路线会不会发生冲突,如果有冲突就踩刹车或者绕着走。
然而,真实的路面上会有各种意外。Google一直在训练自动驾驶技术,他们遇到过各种各样奇怪的情况。有一次有几个小孩在高速公路上在玩青蛙。还有一次,一个残疾人,坐着电动轮椅,在路中间追逐一只鸭子,鸭子绕圈跑,她也绕着圈追。那你说像这种情况你能一下子就准确预测这些人的行动路线吗?自动驾驶汽车识别路边的物体,都是靠把激光打到各种东西上再反射回来。可如果在下雪或者下雨,激光可能打到雪花或者雨滴上反射,汽车就可能对周围物体有重大误判。
计算机能不能保证看懂路边标记限速、慢行的交通标志牌?图形识别技术非常难,曾经,Google自动驾驶技术把奥巴马夫人米歇尔给识别成一只猩猩,贻笑大方,而且假如标志牌有损坏,或者上面被人贴了小广告,那汽车就很可能无法识别。
2016年,一个特斯拉车主违反规定,把车完全交给自动驾驶,结果因为汽车没有识别出来前面的一辆白色卡车,它可能以为那是天上的白云或者别的什么东西,司机当场死亡。当然这是司机犯了错误,但这恰恰也说明自动驾驶技术非常容易遭遇意外。
但是,“大视觉模型”却可能改变这一切 。
2023年9月,OpenAI发布了测试版的GPT—4V,能看懂图片,能解读电子竞技比赛。也就是说,GPT对图像和视频中的各种事物有了很强的理解能力,在测试中,让GPT—4V看不同驾驶场景的图像和视频都获得了惊人的突破,表现出了超越现有自动驾驶系统的潜力。
而且,不只是识别数据,大模型还能生成自动驾驶数据。比如,一家来自英国的自动驾驶公司Wayve就做出了尝试,他们开发了一个名叫GAIA-1的生成式AI模型,人们输入视频和文本,AI就会根据需求创建逼真的驾驶视频。
GAIA-1可以学习和理解有关驾驶的很多概念,包括汽车、行人、道路布局、交通灯、建筑物等等,能够生成很多复杂路况,对走视觉路线的自动驾驶系统非常有帮助。
值得一提的是,来自UC伯克利和约翰斯·霍普金斯大学的研究人员,提出了一种全新的建模方法,可以在不使用任何语言数据的情况下,训练大视觉模型。
简单来说,就是大视觉模型只需看图训练,就能理解和处理复杂的视觉信息,不用依赖语言数据。可见,大视觉模型的进程才刚刚开始,它有巨大的潜能尚待挖掘,这对特斯拉的自动驾驶纯视觉方案是个巨大的利好。
为什么我劝你别太高估大模型了
今天,在自动驾驶领域,各种概念层出不穷,每当有新技诞生,都会有人惊呼,全新的时代要诞生了!
但实际上,大部分人没有人意识到,自动驾驶的边界就是人工智能的边界,而人工智能的边界是数学的边界,没错,数学是有边界的。
1931年,数学家哥德尔认为,许多数学家试图构建一个既完备又一致的数学体系,这样的的努力方向,是错误的,数学体系不可能既完备又一致。也就是说,保证了完备性,结论就会矛盾;保证了一致性,就会有很多结论无法用逻辑推理的方法证明。这提醒人们,让人们知道,数学不是万能的,世界上很多问题不是数学问题。
比如,你正在以很快的速度开车,突然发现前边有一群小学生在马路上打闹。要避让这些小学生,你就会撞到路边的建筑物墙上,而如果撞墙,你的生命安全就面临危险。请问在这种情况下,你是选择撞墙还是选择撞向小学生呢?
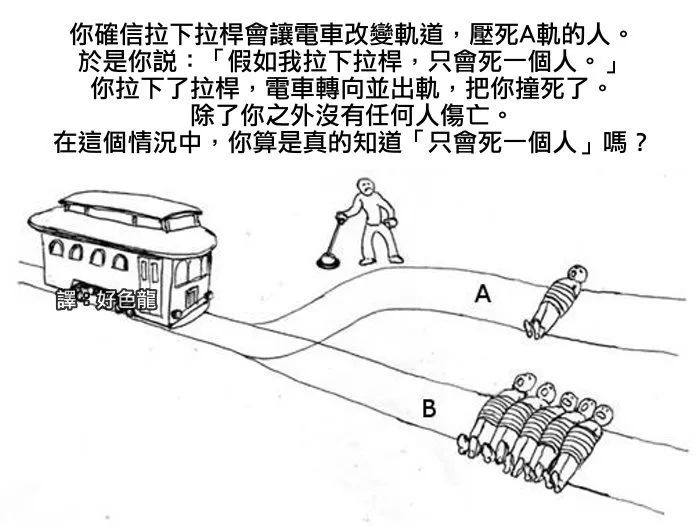
如果汽车厂商告诉你,我们这个车就是讲道德的,我们的自动驾驶系统在这种情况下一定会首先确保行人的安全,请问这样的车你会买吗?
你会让汽车做决定,牺牲你自己吗?可见,这是一个伦理道德问题,没有标准答案,人工智能再强大,也无法计算这样的问题。
其次,许多情况,无论用什么模型,用多么强的算力,也都算不出来。
在数学上,还有一个经典命题,1900年,数学家希尔伯特就提出过一个疑问:对于某一类数学问题,有没有一个方法,通过有限步,就能判断它有没有解?根据希尔伯给出的结论,很多数学问题,就算有算法,但有没有解是不知道的。
实际上,自动驾驶就属于这类问题,到底有没有解,我们不知道。
今天,所有专家都在说,只要数据够多,自动驾驶大模型早晚能成熟,实际上,对自动驾驶系统来说,大部分情况下,能用2%的数据就能训练一个能解决路面80%的情况的自动驾驶系统,但是剩下那20%的情况,你就是再用再多的数据也未必能解决。
比如马斯克的纯视觉FSDV12,在想象中,纯视觉方案有现成的AI算法可以模仿,但实际量产过程中有无数的细节需要完善,想象中,只要在逻辑上做到完美的算法就行了,但实际上算法需要大规模的数据喂养。
要知道,马斯克对特斯拉FSD倾斜了无数资源,比如,在FSD的开发过程中,特斯拉积累了超过90亿英里使用里程,这是全球最大的自动驾驶数据来源;为了利用这些数据,特斯拉不断扩充其超算集群,到处挖顶级AI工程师,自研算法、芯片和大算力GPU。
但即便如此,你也未必能喂得出来,要知道,马斯克曾公开表示,他低估了纯视觉方案的难度,他感到非常抱歉。
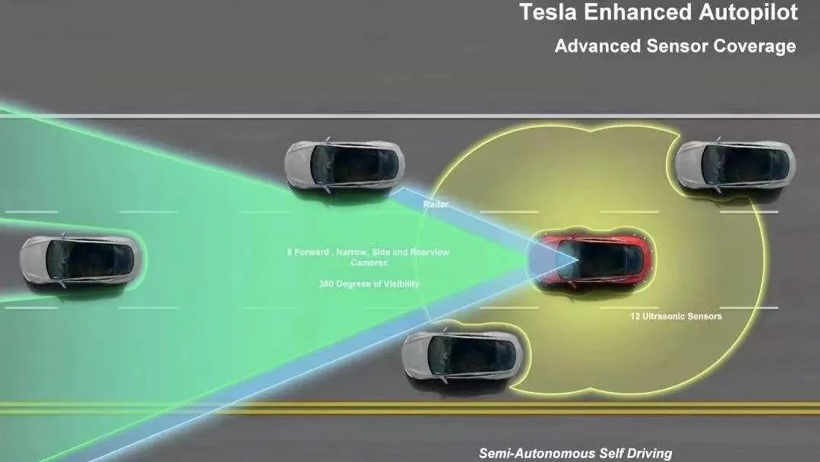
为什么会这样?比方说,美国50个州都有各自的交通法规,各地的气候条件和路况都不一样,这还不算美国和中国更不一样。这意味着什么呢?这意味着在一个地区训练出来的自动驾驶方案,换一个地方就完全没用了。所以任何自动驾驶大模型其局限性都很大,不能通用,你必须在每一个地区都采集大量的数据才行。
进一步说,即便算力增加也无法解决自动驾驶大模型的普适性问题,计算能力增加,原来可以计算的问题会算得更快,甚至瞬间解决,但是不可算的还是不可算。
我们打个比方,你如果有一台制冷机,可以将温度降低。如果你有一个超大功率的制冷机,温度降低得会快得多。但是,用再多、再大的制冷机也不可能将温度降到绝对零度以下,因为那是物理学的一条边界。
总结而言,由于数学的边界无法被突破,所以今天任何的自动驾驶方案,大家可千万别入戏太深。